Binnen de loonaangifteketen wordt veel onderzoek naar de datakwaliteit van inkomensgegevens uitgevoerd. Als onderdeel hiervan is in 2017 en 2018 een tweetal innovatieve producten met betrekking tot anomaliedetectie ontwikkeld. Anomalieën zijn gegevens in een dataset die niet aan het normale patroon lijken te voldoen en om die reden mogelijk interessant zijn. De resultaten van het uitgevoerde onderzoek zijn zowel praktisch bruikbaar als interessant vanuit wetenschappelijk oogpunt.
Goed onderzoek naar de kwaliteit van de loonaangiftegegevens is van groot belang. Veel partijen maken gebruik van deze data, onder andere als basis om belangrijke beslissingen over burgers en organisaties te nemen. Het belang van de kwaliteit van gegevens zal de komende jaren alleen maar toenemen, onder andere omdat de automatiseringsgraad van veel organisatorische processen nog altijd hoger wordt.
Om deze redenen worden op dagelijks basis analyses van de kwaliteit van de loonaangiftegegevens uitgevoerd. Veel van deze analyses zijn sterk regel-gedreven, aangezien de wetgeving een goede basis biedt voor het opstellen van verificatieregels. Het is echter ook mogelijk gebruik te maken van geavanceerde ‘analytics’ om zo op een totaal andere en sterk data-gedreven wijze naar het kwaliteitsvraagstuk te kijken. Een slim algoritme kan zelfstandig een analyse op de gegevensverzameling uitvoeren en zo patronen én uitzonderingen op die patronen ontdekken. Op deze manier kun je je als gegevensbeheerder laten verrassen, omdat het algoritme op een eigen manier en zonder vaste of van te voren opgestelde regels naar de gegevens kijkt. Dit faciliteert een analyseproces met meer serendipiteit en het opdoen van onverwachte inzichten.
Dit is in de kern wat anomaliedetectie doet, namelijk het zoeken van vreemde en opvallende gevallen in een gegevensverzameling. De anomalieën die gevonden worden, zijn niet per definitie fout of verdacht. Het zijn afwijkingen van de standaard patronen. Een dergelijke data analyse kan daarom goed helpen je gegevens beter te leren kennen. Bovendien zullen bepaalde anomalieën wel degelijk fouten betreffen, die betrekking hebben op echte problemen. In ons onderzoek bleek een aantal van de door het algoritme gevonden afwijkingen inderdaad op fouten in de loonaangiftegegevens te wijzen. Ondertussen hebben we daarom ook de programmatuur aangepast om te voorkomen dat deze fouten in de toekomst weer kunnen optreden. Dit zal hieronder in meer detail worden toegelicht.
Typologie van anomalieën
Een van de opgeleverde resultaten is de typologie van data anomalieën. Dit conceptuele raamwerk biedt een fundamenteel inzicht in de verschillende soorten afwijkingen die men in datasets kan tegenkomen. De typologie is geïnspireerd door de loonaangifte, maar is algemeen toepasbaar en kan als zodanig op alle gegevensverzamelingen toegepast worden.
Anomalieën zijn gegevens in een dataset die niet aan het normale patroon lijken te voldoen en om die reden mogelijk interessant zijn. Zo kan het zijn dat deze vreemde en afwijkende gevallen wijzen op foute gegevensinvoer, een verstoord verwerkingsproces, fraude of belangrijke trendbreuken in de echte wereld. De typologie definieert een zestal basistypen anomalieën.
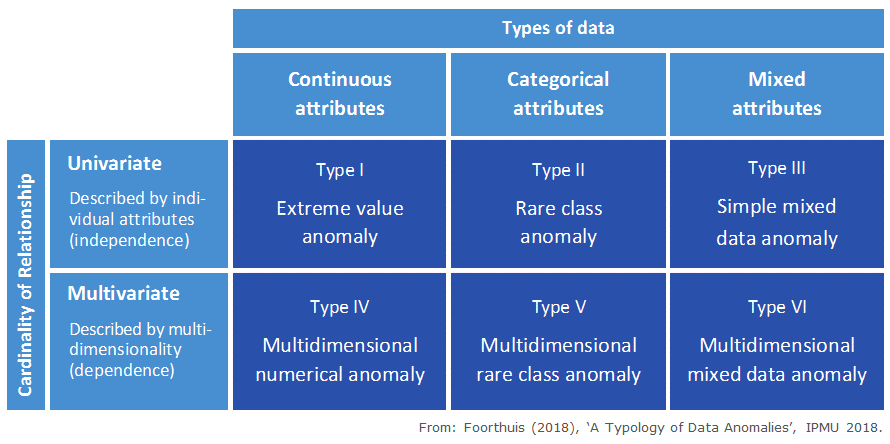
Beeld: © Ralph Foorthuis
Het gaat te ver om alle typen anomalieën hier in detail te bespreken. Op deze webpagina en in het wetenschappelijke artikel kan meer informatie over de typologie worden gevonden, inclusief diverse voorbeelden.
De typologie dient een aantal doelen. Een belangrijk doel is het verschaffen van inzicht in wat data anomalieën zijn, op welke manieren zij zich kunnen manifesteren in datasets, en wat patronen en afwijkingen zijn. Daarnaast levert de typologie een raamwerk voor het evalueren van algoritmen voor anomaliedetectie, zoals het SECODA-algoritme dat hieronder wordt toegelicht.
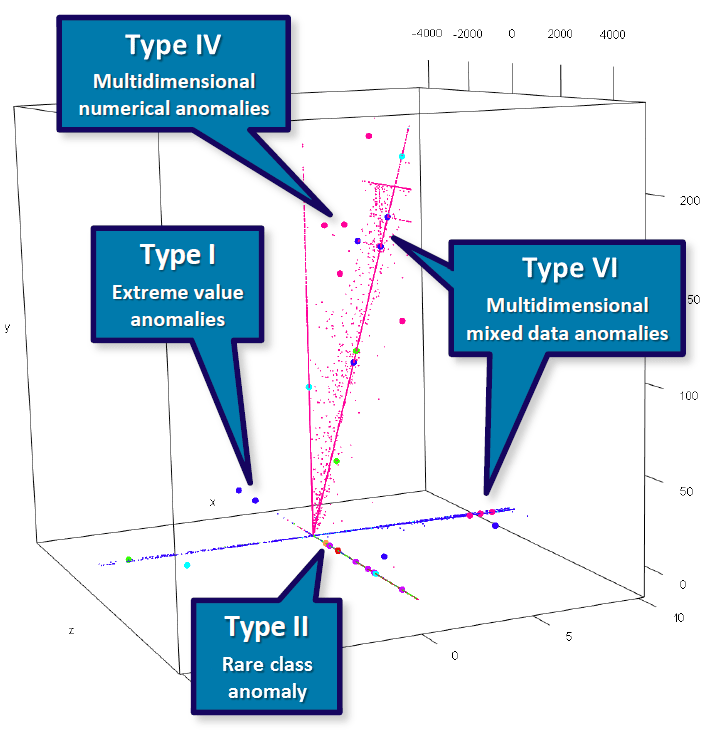
Beeld: © Ralph Foorthuis
Het diagram is een visualisatie van een aantal gegevens uit de Polisadministratie. Onder de gegevens zit ook een aantal anomalieën. Op deze paginaworden de getoonde voorbeelden in meer detail besproken.
Het SECODA algoritme voor anomaliedetectie
Als onderdeel van het onderzoekstraject is er ook een nieuw algoritme voor anomaliedetectie ontwikkeld, SECODA genaamd, en zijn hiermee diverse experimenten uitgevoerd. Het algoritme is in staat de zes typen anomalieën te identificeren die in de typologie worden onderkend. SECODA analyseert de gegevens in een aantal processlagen, waarbij telkens diverse transformaties en berekeningen worden uitgevoerd.
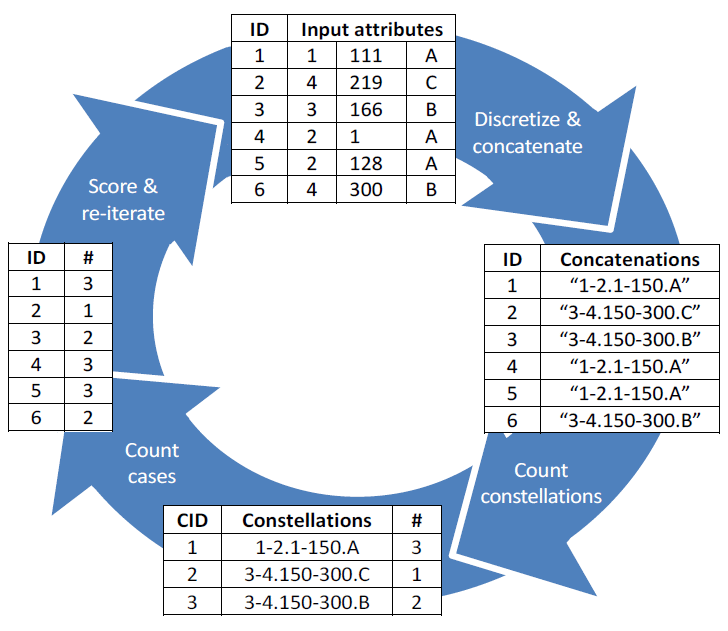
Beeld: © Ralph Foorthuis
De uitgevoerde experimenten tonen aan dat SECODA, en anomaliedetectie in het algemeen, een praktische bijdrage aan de gegevenskwaliteit kan leveren. Uit een analyse op een steekproef van de loonaangiftegegevens kwam een aantal interessante kwesties naar voren. Zo bleek bijvoorbeeld dat de anomalieën die door SECODA geïdentificeerd waren vaak correspondeerden met kandidaat-controleregels die eerder waren opgesteld door de data analisten die de gegevenskwaliteit op dagelijkse basis verifiëren. Blijkbaar vindt SECODA dus inderdaad opvallende en interessante gevallen. Bij nadere analyse bleek verder dat, net als in het geval van de kandidaat-regels, lang niet alle afwijkingen ook daadwerkelijk als onbetwiste fout bestempeld konden worden. Eén groep door SECODA gevonden anomalieën bleek echter wel degelijk een echte tekortkoming te representeren. Dit betrof geen fout in de aangiften of in de opslag hiervan in de Polisadministratie. De oorzaak van de tekortkoming bleek het feit dat de export uit de Polisadministratie minder volledig was dan mogelijk. Vanuit technisch opzicht was deze export correct. Echter, doordat de afzonderlijke Inkomstenverhouding- en Inkomstenopgave-objecten elk hun eigen tijdslijnen hebben (en overigens ook móeten hebben), sluiten deze in bepaalde uitzonderingsgevallen niet altijd perfect op elkaar aan. Technisch gezien ligt het voor de hand bepaalde waarden in die gevallen bij een gegevenslevering dan leeg te laten. Echter, qua betekenis weten we dat sommige gegevenselementen wel degelijk in de Polisadministratie bekend zijn. Daarom is besloten de leveringsprogrammatuur zodanig aan te passen dat de lege cellen in die gevallen alsnog gevuld worden. Inmiddels worden gegevensleveringen dan ook beter en rijker gevuld dan voorheen.
Op deze webpaginaen in het wetenschappelijke artikel kan meer informatie over SECODA worden gevonden. Het algoritme is als gratis open source software voor de R analyseomgeving te downloaden, evenals diverse voorbeelden en datasets. Zie ‘SECODA resources for R’ op deze pagina.
Publicaties
De typologie en het algoritme zijn niet alleen relevant voor praktijkgerichte analyses ten behoeve van datakwaliteitsverbeteringen of fraude- en foutdetectie, maar zijn ook interessant vanuit een academisch oogpunt. De artikelen waarin de typologie en het algoritme zijn beschreven, zijn dan ook geaccepteerd voor belangrijke internationale wetenschappelijke data science conferenties. De volgende artikelen kunnen worden gedownload: het SECODA algoritme, identificeren van verschillende typen anomalieën middels verschillende algoritme-settings, en de typologie van anomalieën.
Beeld: © Ralph Foorthuis
Over de auteur
Dr. Ralph Foorthuis is lead architect van UWV Gegevensdiensten. Als zodanig houdt hij zich onder andere bezig met de Polisadministratie en de loonaangifteketen, het UWV Datawarehouse, analytics, webportalen, gegevensleveringen, integratie, informatieplanning, systeemontwikkeling en informatiebeveiliging. Ralph is aan de Universiteit Utrecht gepromoveerd op het vakgebied van de Information Systems en publiceert artikelen over enterprise architectuur en data analyse. Zie www.foorthuis.nl voor een overzicht van zijn publicaties.
Referenties
Foorthuis, R.M. (2018). The Impact of Discretization Method on the Detection of Six Types of Anomalies in Datasets. Proceedings of the 30th Benelux Conference on Artificial Intelligence (BNAIC 2018), November 8-9 2018, Den Bosch, the Netherlands.
Foorthuis, R.M. (2018). A Typology of Data Anomalies. Accepted for Presentation at IPMU 2018, the 17th International Conference on Information Processing and Management of Uncertainty in Knowledge-Based Systems, Cádiz, Spain. DOI10.1007/978-3-319-91476-3_3
Foorthuis, R.M. (2017). SECODA: Segmentation- and Combination-Based Detection of Anomalies. In: Proceedings of the 4th IEEE International Conference on Data Science and Advanced Analytics (DSAA 2017), Tokyo, Japan, pp. 755-764. DOI: 10.1109/DSAA.2017.35
Foorthuis, R.M. (2017). Anomaly Detection with SECODA. Poster Presentation at the 4th IEEE International Conference on Data Science and Advanced Analytics (DSAA 2017), Tokyo, Japan. DOI: 10.13140/RG.2.2.21212.08325